Anatomy of test automation 2nd Edition
A year or so ago, I had some ideas about the broader topic of Automation, and how it takes more than a sequence of steps with some assertions to make it successful. My original post can be found here: https://dev.to/dowenb/anatomy-of-test-automation-e9o
Rather then bring the original post over to my personal blog as is, I’m going to attempt to update it and make it easier to consume.
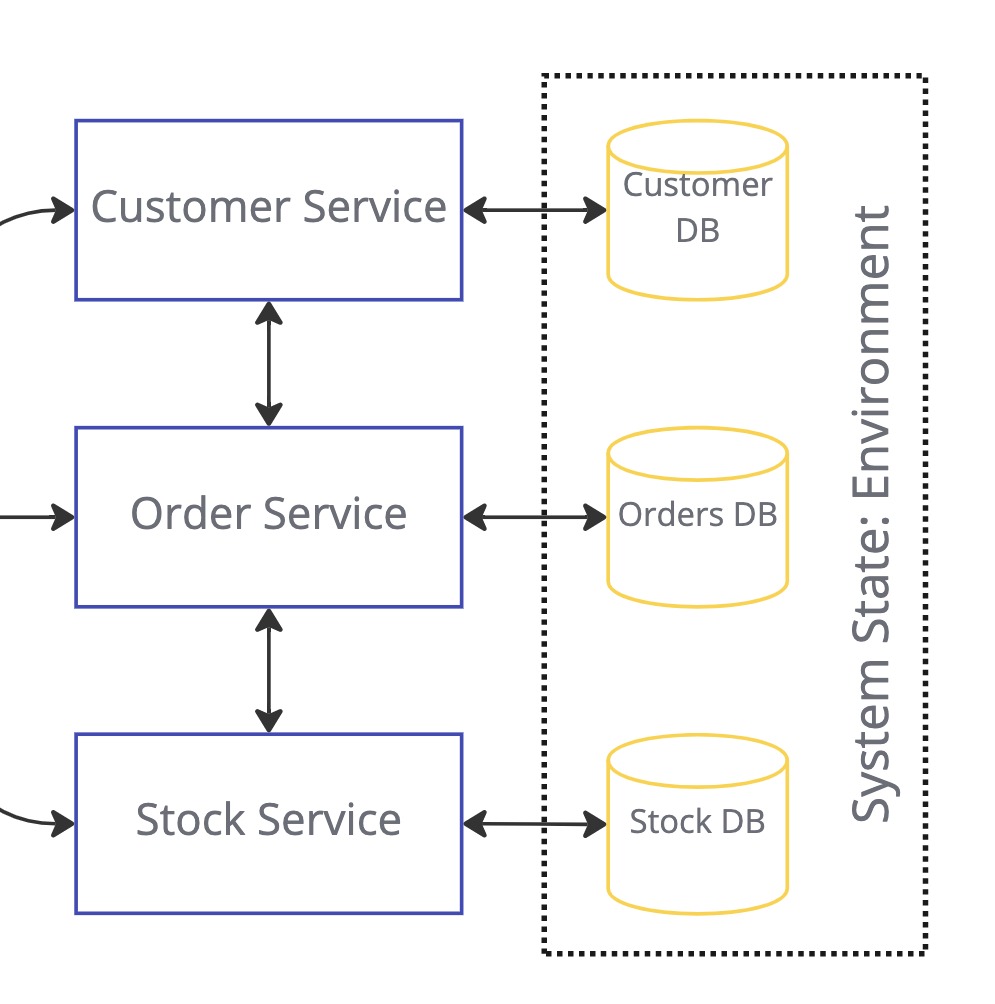
System under test and supporting environment

In the beginning, you need the correct version of the System Under Test. In this example diagram, we can see a hypothetical systems diagram that shows the environment, if the System Under Test, was the Audit Service.
This maybe as simple as taking the latest build of a single isolated service. More likely, this will involve getting matching versions of multiple services that work together to form a system.
This task alone may not be trivial, more than likely it can be automated with help of a Continuous Integration (CI) platform. Something like Jenkins that can be configured to kick off builds when you commit changes to source control.
There are many useful technologies you can use to help you here, such as Docker, to spin up environments built of one or many components.
There are a few different approaches you can take to test environments, these generally fall into shared or isolated. Each has different advantages, let’s take a look.
Use shared, long lived environments
Shared environments are useful because they can often support being used by multiple people at once. This means the whole team, or even multiple teams can be looking at the same consistent snapshot of the system, and it’s different builds at once. This means you can have a shared experience of the system, and it can avoid the “works on my machine” problems when reproducing issues.
You can also use shared environments to work with external teams or customers, these are sometimes called integration environments and may be abbreviated to int.
Another advantage of such shared, longer lived environments is they may look closer to a production setup, although typically they are scaled down for cost purposes.
The downside of shared environments are:
- Difficult or impossible to isolate test date and shared state
- Requires maintenance if test data nears clearing out or it gets corrupt
- Needs updating with latest versions as new things get release and when taking a new version this may interrupt testing in progress
Shared environments that have shared state, e.g databases, are typically sub-optimal for use in automation, but can support exploratory testing.
The cost consideration for long-lived environments, is that depending on hosting they may be costing money while they are not being used. This can be somewhat mitigated, if they can be shutdown automatically outside of hours of use.
Isolated, on demand environments
Isolated environments that are created on demand, live for only as long as they are needed and are then destroyed offer huge advantages to test automation.
On demand environments that are built as needed, often supported by container technology such as Docker, can consist of multiple services. This maybe a combination of software build by your team, other teams in the company, and supporting services such as Databases, Queuing, Proxies, Load balancers, and mocks of third party systems.
On demand environments may also be used for exploratory testing, where experiments can be run against a configured set of versions for the various components of the system under test.
The cost consideration for isolated environments, is that each new environment adds cost, because all parts of the system under test and supporting services are spun up together. This is why typically, isolated environments are created on-demand and are short lived. They serve their purpose, and are then removed. This can be very cost effective overall.
One disadvantage of on-demand environments is the extra time it takes to spin up, this can add minutes to your automation run, before tests have even started.
Isolated or Shared Environments?
The two are not mutually exclusive, you could have isolated environments for automation, and shared environments to aid exploration. It really depends if you are optimising for cost, freedom of configuration, isolation or speed.
However you approach it, getting the environment and setup for the system under test right is not a trivial task, and requires investment. If you have infrastructure, ops or devops type folk at work, make use of them. If you’re really lucky, you might have a platform engineering team that can set-up some of this magic for you.
Test scenario
Okay, the big one, once we have our environment all setup and supporting our SUT, we can focus on what to test.
Problem solving
You likely have some kind of motivation for introducing test automation. Take some time to make your desired outcomes explicit, and figure out how you might measure your success.
Maybe you are hoping to release faster? or you might be interested in providing faster feedback for problems that are normally caught late, or not caught at all!
Risks and choosing what to test
Before we break down our tests, let us take a moment to consider what problem we are trying to solve, and what risks we want to address.
It has often been said before, that simply trying to automate a stack of existing regression test scripts is a receipt for a failed automation effort. But what alternatives exist?
- Take a risk-based approach, use techniques such as Risk Storming to identify key quality aspects and the risks to them, and focus your efforts there
- Identify tests that are error prone or difficult to run by hand, and focus there
- Identify tests where automation can bring value due to an expanded range of inputs, or simulate realistic load
- Identify the path though your system under test that gives the most business value, for example completing an order, the critical paths that must work, and focus there
- Play The Nightmare Headline Game from Explore It! by Elisabeth Hendrickson
Once you have identified some risks, or high value focus areas, you will need to prioritise where to start. If you don’t already have your own generic approach to prioritisation, fear not! As James Thomas has kindly shared his, in this blog post Order, Order!
Prerequisites
In addition to all the setup you’ve done to get this far you might still need a bit more. Maybe you need some Customers, and Stock, so you can exercise Orders?
Test data
If your inputs and outputs are static, this might be trivial. For me, I often work with non trivial test data that requires some level of templating.
I often need to make sure dates represent today, even if I wrote the test and captured the data months ago.
In some cases test data can be generated automatically using libraries like faker. I know some tools, like Mockoon include Faker out the box.
Once you know what shape your test data may take, you might want to create scripts to pre-seed databases if you are using isolated environments. You may also wan to reset data to a known state, if you are using shared environments.
System state (Given)
Now your going to want to get your system into the starting state.
Some examples:
- A customer exists
- Stock is available
- The customer has no outstanding orders
This is something your automation framework really should handle.
Action (When)
This is the core of the test. Stimulating the users action or a sequence of multiple actions that we expect to make some change to the system state.
Examples:
- New customer is registered
- Order is placed
- Stock is allocated
Assertion of expected result (Then)
This is where we have a coded assertion. I don’t mean we need to be using a programming language, but we need to have an unambiguous way to choose if the actual results we got are what we expect.
If they match our coded expectations the test passed, otherwise it falls. The term for the source of knowledge you used to determine if a test past is often called an oracle, you can learn more about oracles in this Ministry of Testing 99 second introduction:
https://www.ministryoftesting.com/dojo/lessons/99-second-introduction-to-oracles
While we can make test smart to an extent and we can look for shapes and ranges, ultimately we can only assert on what we can expect.
Logging and reporting
Analysing logs and making reports can definitely be fully or partially Automated.
This might take the form of some Console output that can be captured by your CI System and be linked to a build. It could also take the form of a HTML report, complete with graphs, screenshots, API responses to even video recording.
What you will probably miss is the contextual logging. The logs from the dependencies and more distant parts of your SUT. This can also be captured and logged, but takes a fair amount more thought.
Minimal Experiment
Of course this maximalist description describes pretty much an end to end or system integration test.
As expert’s like Mark Winteringham, Richard Bradshaw and Alan Richardson would tell you, you can get great value from Automation and Tools to support your testing way short of an end to end test.
I’ve done this myself on plenty of occasions by creating tools to capture or generate test data, of by mocking APIs to support my Exploratory Testing.
I would encourage you to start with the smallest possible experiment that brings you value, and then build up to a more complete suite of test automation over time. Your team will benefit from faster feedback from tooling quickly, before you finish a full setup.
Automation strategy requires support
Building software is a team game, and Software Quality even more so. I encourage you to work with teams and individuals across your company to share expertise and get help. If you’re lucky, you maybe have some type of platform engineering team who can help you with the CI/CD setup and building test environments.
Getting investment to support an automation strategy takes effort, especially, as I hope you can now see, it takes a lot more to get right then simply writing a few tests in a framework and hoping for the best.
If you were not convinced already that to succeed, an automation strategy needs support and buy in from many people in various roles, I hope you’re now a convert. And I wish you luck getting the help and support you need to make automation a success in your team.
Cover Photo by Karolina Grabowska